
AI Personalization: Building Authentic Writing Skills

The twelve-word wake-up call
Why AI personalization defaults fail at capturing authentic voice
Default AI output is fine. That is the problem.
Developing effective claude skills means recognizing that default output is the median of every blog post on the topic — same opening shape, same vocabulary, same three-item lists, same closing flourish. The reader has read it before. The reader does not need to read it again.
Automated content generation without calibration produces median content because that is the safest play given no signal about who is writing or who is reading. This lack of ai personalization reads as boring. Boring is the AI tell.
I learned this the slow way. I shipped post-shaped objects for months. The math was bad — hours of editing per post, zero readers staying past the first paragraph. Developing effective claude skills requires moving beyond this default output.
The moment I knew settings weren’t enough
A YouTube blogger I came across pulled up Claude Skills and a voice file and personalized AI output in a way I had not tried. The output sounded like a person. Mine still sounded like a press release that had learned to say “I.”
I had been turning knobs on the prompt. Temperature, top_p, the length of the system message. None of it touched the actual problem. The voice was missing entirely. I had been blaming the model for output I had under-prompted, when the real issue was my prompting technique. Effective personalization requires more than technical parameters—it demands understanding how to craft prompts that capture authentic voice.

What “comprehensive” really meant
First-pass AI-generated GRASPPY content used the word “comprehensive” twelve times in 800 words. I ran grep. Twelve. Not “many.” Not “several.” Twelve discrete instances of a word that did no work.
It appeared as the H1 of one post: “The Comprehensive Guide to Knowledge Management.” It opened three different sections of another — “A comprehensive approach to memory,” “Our comprehensive pipeline architecture,” “A comprehensive solution for knowledge workers.” It sat in the meta description of a third. None of those uses carried information. The word was a filler masquerading as a virtue.
The moment I ran grep and saw the number was the moment I stopped tweaking sliders and started writing constraint files. (Twelve uses in 800 words is one every 67 words. I had not been editing the AI. I had been laundering its defaults.) That number changed how I thought about AI prose and developing my ai writing skill. The default settings were not bad. They were aggressive about a specific kind of bad. I added “comprehensive” to a ban list, then “leverage,” then “seamless,” then “unlock.” The list keeps growing. So does the quality of ai personalization content.
AI Helps the Writer Think Clearly
AI writing tools are not just shortcuts for producing more text. Used well, they become a practice partner: helping clarify ideas, improve structure, adjust tone, catch weak spots, and give immediate feedback while the thought is still fresh. That kind of support matters because writing is not only about grammar; it is how we explain decisions, build trust, collaborate with others, and turn rough thinking into something useful. The strongest use of AI is not replacing the writer, but strengthening the writer’s ability to think clearly, revise faster, and communicate with more confidence.
As goFLUENT writes, “Strong writing skills are essential for career growth and business success. By combining AI’s efficiency with human insight, you can master the art of clear, impactful communication.”
How a YouTube demo changed the approach
Claude Skills + Personalization Insight
The blogger’s setup was simple. A voice reference. A humor reference. Stats. Stories. Opinions. Five files, each one narrow, each one read by the model before it produced a single sentence. AI personalization meant nothing in the abstract — five specific files made it real.
The insight (which my therapist would footnote): the issue was never the model. The issue was that I had been asking the model to invent a voice it had never been given. With Claude Skills in place, the model stopped guessing.
Why layered reference files matter
A single “be friendly and conversational” instruction does nothing. Five layered files that say what to write, which jokes land, which numbers are real, which stories are real, and what I actually believe — those land.
Each file is a specific constraint. Stacked, they make the surface of the output narrower. Narrower means more like a person.
The gap between capability and execution
The capability gap between Claude in 2024 and Claude in 2026 is real but largely irrelevant for this problem. The execution gap — what you actually feed the model and what it does with that — is where most of the quality lives.
I had been waiting for a better model when what I needed was better inputs.

The old pipeline versus the new one
What we were doing before
The old flow: write the post, then optimize for SEO afterward. The AI generated whatever the topic suggested. I would read it, edit it, ban a few phrases, paste keywords in places that felt natural, then publish.
The order was wrong. Edits multiplied. The post that emerged from three rounds of patching still sounded like the first draft, lacking the refined ai writing skill that comes from proper planning.
Why generic templates breed generic posts
A template that asks for “introduction, body, conclusion” produces an introduction, a body, and a conclusion. None of them earn their place. The body sounds like the introduction. The conclusion restates the introduction.
AI is good at templates. Too good. Generic templates breed generic posts because every section ends up doing the same kind of work, regardless of the specific ai writing skill being applied. This is why ai personalization requires moving beyond rigid structures toward more adaptive approaches.
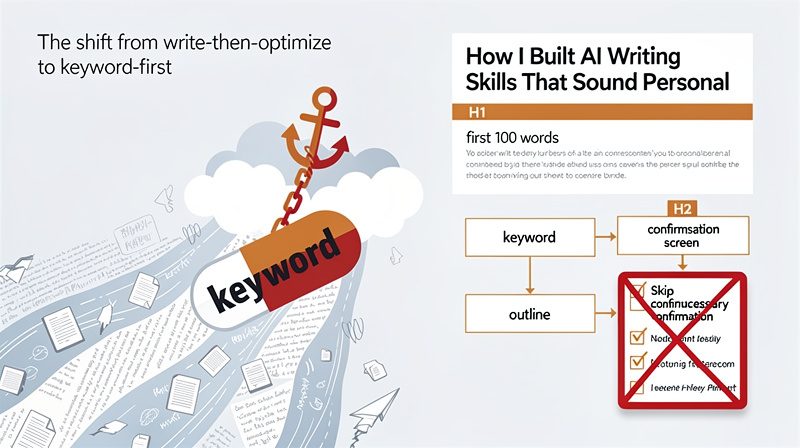
The shift from write-then-optimize to keyword-first
The new flow picks the keyword first. Validates it before any prose runs. Treats the title, the H1, the first 100 words, and at least one H2 as anchored to that keyword from the start.
The first draft of this flow had one extra step in the middle. After picking keywords and before generating the outline, the AI would re-summarize the brief and ask the user to confirm the “final” version. It looked sensible on a whiteboard. A pause to verify. Best practice.
I read the screen and saw what was actually happening. The user would land on a screen that showed them what they had just typed two clicks ago, summarized by an AI that had not yet done any real work, asking them to approve their own input back to themselves. The reason was simple: I see no value in it. Remove it.
The flow lost a step. The post quality went up. The whiteboard had been wrong. This kind of ai personalization requires constant iteration to find what actually serves users versus what sounds good in theory.
Five reference files that anchor voice
The voice file — tone, cadence, personality
The voice file is the spine. It says who is writing, how their sentences move, which phrases they use, which they never use. A canonical paragraph at the top — one read-aloud passage that sets the rhythm — followed by an explicit ban list.
Mine has a personal section first. Solo founder. Silicon Valley. 35 years corporate. Optimistic past the point of reason. ADD-focused, lazy enough to automate everything. The AI reads that section before it writes a single sentence. The output downstream is dramatically less anonymous than what comes out of “be friendly and conversational.”
The ban list does more work than the canonical paragraph. (Most voice instructions are too polite to ban anything. Mine bans 14 specific words and 7 specific patterns.)
The humor file — when to lean in, when to hold back
Humor is the loudest tell that a human wrote the post. The file specifies a frequency budget — a 2,500-word post lands roughly 5-7 dry self-jabs and 3-4 parenthetical asides — and a target tone.
The target tone is specific: a 50-something corporate veteran turned solo vibe-coder, mid-fifth-coffee, talking to one friend who is about to make the same mistake. Not LinkedIn. Not stand-up. Read aloud before shipping.
The file also bans things. No exclamation marks. No emojis. No therapy-speak. No edgy. Self-deprecation always, never punching down at the reader. The reader is here because they have the same problems, not so I can roast them for having them.

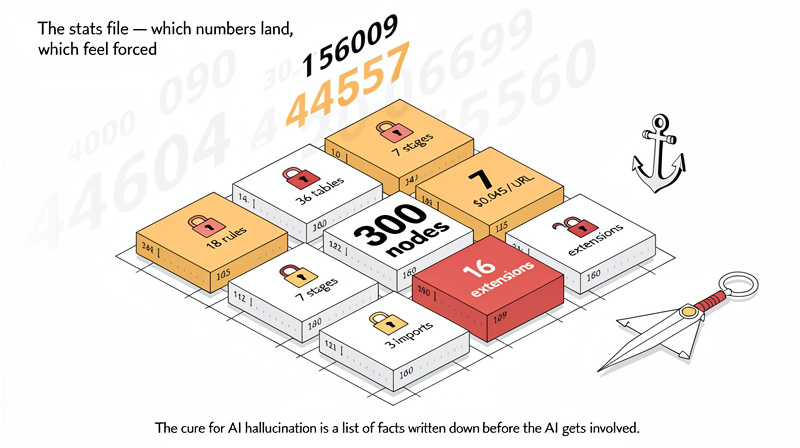
The stats file — which numbers land, which feel forced
The stats file holds the real numbers. Version 8.98.0. 18 active rules. 36 PostgreSQL tables. 7 pipeline stages. $0.045 per per-URL competitor analysis. 16 supported Chrome extension platforms plus 3 via Markdown Import.
The rule is exact, not rounded — “300 nodes” not “around 300.” If a fact is not in the file, the post leaves it out. The cure for AI hallucination is a list of facts written down before the AI gets involved. (The cure is not “ask the AI to be careful with numbers.” That has never worked. Not once.) This approach transforms ai writing skill from unreliable to precise.
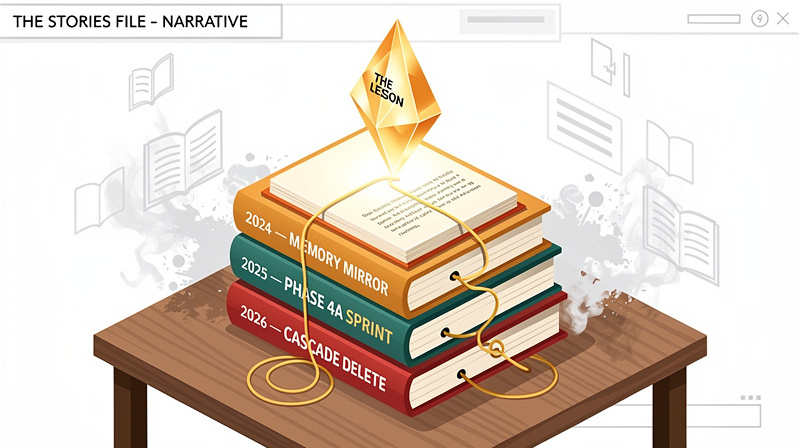
The stories file — narrative patterns that stick
Six recurring stories, each with a date, a specific detail, and a lesson. The 2026 CASCADE delete incident (a “cleanup” instruction that deleted 300 nodes across 7 parts). The Memory Mirror. The “twelve in eight hundred” cleanup. The Phase 4a build sprint. Each one with a “Use when writing about” list so the AI knows when a story fits and when it does not.
One story per post, no more. Multiple stories feel like a war-stories binge. The lesson is the part that travels. A bug story without a lesson is anecdote. A bug story with a lesson earns its keep and demonstrates claude skills in action, creating effective ai personalization through authentic experience.
The opinions file — what you actually believe
Opinions are seasoning. One per post, max. Every opinion in the file is backed by a number or a story — that is the rule. I cannot deploy a take I have not earned.
Seven opinions, each one specific. “LLM-era SEO is just SEO. The black box is content quality.” “Vibe coding fails when memory fails.” “Most blog tooling exists to make the tool’s owner feel productive.” Each one comes with backing evidence and a usage note (“use when writing about X, never deploy without naming Y”).
The opinions file is a forcing function. It keeps the post honest and sharpens my ai writing skill. It also keeps me from deploying the same opinion in two posts back-to-back. This approach creates a form of ai personalization in my content — each opinion becomes a unique signature that reflects my specific perspective and experience.
Keyword-first flow: gate, candidates, research
Why keyword selection comes before the first prompt
The AI writing skill works better when it knows what the post is anchored to. A primary keyword and up to five secondaries picked before the first prose call means the title, the H1, and the opening 100 words land on the anchor without retroactive surgery.
Picking the keyword after the draft is the same as picking randomly.
Candidate research and competitive structure
Each candidate keyword goes through real research. Search volume. Difficulty. Intent. The AI suggests five candidates from the brief; I pick the primary and up to two secondary anchors from there, or research a custom one.
The rule that earned its place: every keyword has to be two to three words. Four-word phrases have zero search volume. A research call on a worthless keyword still costs the same as a research call on a good one.

Building the research layer into the generation step
All five picks auto-bookmark to the user’s library. That single rule removed an entire class of “where did my picks go” friction.
The keywords then appear in the writing prompt at the top level — not buried inside the brief — so the writing AI cannot miss them. This approach ensures claude skills can be effectively leveraged, with the keyword serving as the anchor, not the afterthought.
The preflight pass: catching AI tells before publish
Banned phrases and pattern detection
The preflight runs before the post saves. About 25 banned-phrase regexes, plus pattern detection for seven AI tells — three-item parallel lists, “moreover” and friends, three-adjective verb-clusters, “in conclusion,” and the rest.
Honest example from a flagged draft (I am quoting the AI here, not deploying these words myself):
GRASPPY leverages a comprehensive suite of tools to seamlessly unlock new dimensions of knowledge management.
Three banned phrases in nine words — leverages, comprehensive, seamlessly. Plus “new dimensions” doing zero work. The regex caught it before the draft saved. The section went back to the model for a rewrite at lower temperature. The next attempt landed clean.
(That is one sentence. There were six on the first draft just as bad. The preflight catches what I would have to grep for manually otherwise, helping me maintain natural claude skills throughout the ai personalization process.)

The retry loop with stricter constraints
The rewrite runs at a lower temperature — 0.75 down to 0.55 — with the offending pattern explicitly named in the new prompt. Up to two retries. If the third attempt still fails, the section gets flagged for human review with a specific reason.
Three strikes is enough. At that point the section needs me to look at it, not another retry that might compromise the ai writing skill.
What actually gets flagged and why
The most common flag is the three-bullet trap. AI loves to convert a thought into three bullets even when one sentence would do. The second most common is the “It’s important to note that” opener. Third is the comprehensive family — comprehensive, comprehensive guide, comprehensive overview, comprehensive solution.
The fourth most common is harder to catch with a regex but easy to spot in practice: the AI invents a “best practice” no one asked for. “Best practices include regularly reviewing your knowledge base” — useless, untrue if regularly is undefined, and not anything I said in the brief. That one gets flagged for human review.
Generic AI prose has a fingerprint. A regex catches the obvious version. Human review catches the rest. That is the entire mechanism.

SERP-mimicry: letting research shape structure
How top-3 competitor posts inform outline
When per-URL competitor analysis is linked to a post, the system pulls the top three ranking posts for the primary keyword, scores their average word count, and notes their H2 structure. The outline gets nudged toward the same league.
Not to copy them. To land in the same neighborhood, then beat them on the prose.
When to follow structure, when to break it
Structure is a hypothesis, not a hard cap. If the top three rank for 1,800-word “ultimate guide” posts and you have a sharper 1,200-word angle, ship the 1,200.
Ranking is a long game. The post that matches the cluster gets indexed. The post that is better gets shared. Both matter, and the project that confuses them will optimize for one and lose the other—much like developing claude skills requires balancing technical precision with practical application.
The tension between ranking and readability
Stuffing keywords for SEO and reading well as prose are not the same problem. The preflight catches stuffing — a keyword density above three percent is flagged. The editorial framework catches unreadability through the anti-AI-tell list, helping writers develop better writing skill for personalized content.
They argue. The way they argue is the design. Neither one wins on its own.

When not to do this yet
Why premature calibration is yak-shaving
Building voice calibration before you have posts to calibrate against is yak-shaving with extra steps. The first three to five posts of a default setup tell you which knobs actually need tuning and help develop your ai writing skill.
Building the knobs first means building the wrong knobs. The math isn’t adding up yet — because you have not given yourself any math to add. Effective ai personalization requires actual content to personalize against.
The 3-5 post threshold for knowing what to tune
Three is the floor. Five is the cleaner signal.
After five posts on a default setup, you know which phrases you keep crossing out, which structures you keep rejecting, which numbers you wish the AI had used. That list is the voice calibration brief. Without those posts, the brief is a guess.
Building infrastructure after you know the problem
The right order is post first, calibrate second, build infrastructure third. I did it backwards. I had one job. I shipped infrastructure instead.
The infrastructure works now. It would have worked sooner if I had stopped shipping it and written more posts first.

What we shipped, what we didn’t
The irony of building without shipping
Most blog tooling exists to make the tool’s owner feel productive, not to drive traffic. I am the data point that backs that claim.
Things I built between January and May this year, for the blog specifically: an SEO research module with DataForSEO integration. A keyword bookmark library with full metadata persistence. A per-URL competitor analysis system with citation flow. A Source Material modal that composes prompts from the post’s title plus keywords plus brief plus outline plus universal extraction framing. A preflight pipeline with 25 banned-phrase regexes and a 2-retry loop. An Astro static site at the receiving end. A SyncDoc system that mirrors the database into local folders. A check-in flow with marker discipline. A keyword gate with auto-bookmarking and 3-state UI feedback.
I just published this post you are reading. It is the second one in two months. That is the ratio. Eight months of platform engineering against one published post. (Two, if you count the welcome.md placeholder. I am not counting the welcome.md placeholder.)
Some of that was load-bearing. The keyword gate and the preflight loop genuinely changed the output. Most of it was the trap. The trap is that every feature feels like progress. It is — for the tool. The tool’s progress and the project’s progress are not the same number. The project’s number is post count. The tool’s number is feature count. Mine got out of balance, and the rebalance is the post you are reading right now, written through the very pipeline I will keep judging by whether it produces post number three by Friday. This entire workflow depends on claude skills for content generation and refinement.
Which pieces of the pipeline actually moved the needle
The voice ban list moved the needle. Three regex changes that survive any model upgrade. The keyword gate before generation moved the needle — anchoring the title and H1 from the start instead of patching them after. The preflight loop moved the needle for catching the comprehensive-family tells.
The rest was nice to have for developing ai writing skill in personalization. Nice to have does not pay rent.
Where the infrastructure still feels overbuilt
The Source Material modal is more complex than it needs to be for the value it delivers right now. It is the right shape for a future where I publish four posts a week. At one post a month, it is too much modal for the volume.
I also still have small bugs that prove the infrastructure has outgrown its operator. Last week the SEO Research modal opened and the spinner spun forever — three words of bug report (“Research is stuck”) that turned out to be a state-machine guard I had updated in one place and not the other. The infrastructure is more layers than I can hold in my head at once.
That gap will close one way or another. Either I ship more posts and the modal grows into its job, or the modal stays oversized and I prune it.
Where to start this week
One reference file to build first
Build the voice file first. Not all five. The voice file is the spine — the others amplify it.
Three short paragraphs about who is writing. A twenty-line vocabulary list. A twenty-line ban list. That is a working voice file. You will rewrite it after post three anyway.

The smallest viable preflight check
The smallest viable preflight is one regex: the word “comprehensive.”
Add “leverage” the second week. Add “seamless” the third. By month two, you have a working ban list and a sense of what your model defaults to. Building the full preflight pipeline before you know your model’s defaults is, well — see above re yak-shaving.
How to know if this approach fits your workflow
This approach fits if you are already publishing and the prose feels wrong. It does not fit if you have not shipped post one. The infrastructure is for people whose problem is editing AI output back into their voice. If your problem is shipping at all, ship five posts on defaults first and come back.
Or you could just keep doing it the way I did until last week. I won’t tell.
Related posts

Chat Analysis AI: Six Months of Chats - Any Answer In 10 Seconds
Learn why chat analysis AI matters for organizing your conversations. Discover how to search and preserve your AI chats instead of losing valuable insights.

The AI Workflow Stack Behind GRASPPY (And Why Simple Wins)
Discover the simple AI workflow stack powering GRASPPY's memory system. Learn why choosing straightforward tools over complex architectures delivers better results.
AI Knowledge Management: Build Your Second Brain System
Master AI knowledge management with a second brain system. Learn proven methods to organize AI insights, enhance AI memory, and streamline your workflow.