
AI Knowledge Management: Build Your Second Brain System
Introduction
Why I’m writing this
Last year my browser started to feel like a graveyard. Forty open tabs across four AI platforms, each one holding a conversation I “might need later.” I’d ask Claude something brilliant about database schema design on a Tuesday, then on Thursday go looking for it and end up re-asking ChatGPT because I couldn’t find the original thread. The answer I’d already gotten would sit in the graveyard, exactly where I needed it, invisible.
This is the story of what I built when I got tired of losing my own AI knowledge — an external system that actually remembers where I put things, a second brain that works the way I think. @
It’s also, honestly, the story of twelve months of late nights, a week of lost work that nearly broke me, about a hundred hours of prompt engineering that nobody will ever see, and a product that slowly — then suddenly — started to feel like mine.
I’m publishing this as the first real post in my journal because I wanted to write it down before the shape of the thing fades from memory. If you’re a builder, a solo founder, a researcher, or just someone who lives in AI chats all day — you might recognize yourself in here. I’d love to hear from you if you do.
Recovered content from Introduction
The journey of building GRASPPY has been an exploration into creating a digital repository—a comprehensive system for organizing and sharing AI knowledge in ways that truly serve human understanding.
The problem I couldn’t stop thinking about
My AI memory became my second brain — and then my worst mess
I’ve been a heavy AI user since the original ChatGPT. Writing code, debugging production issues, understanding papers I only half-read in college, drafting emails I didn’t want to write, brainstorming product ideas at 2 AM, working through personal decisions I wasn’t ready to talk to anyone else about. For two years, every meaningful thought I had went through one of these models at some point.

And then, at some point in [early 2025 / late 2024 — pick the real date], I tried to find a specific insight I remembered getting from Claude about a hiring decision I was mulling. I spent forty minutes clicking through my chat history. Couldn’t find it. Asked again. Got a different answer — not wrong, just different, because the model doesn’t remember the context I was in the first time.
That was the moment. I sat there and realized I had been dumping my external memory into a system that had no way to retrieve from it.
The cost wasn’t just inconvenience. It was that I kept having the same conversations. The same “help me think through X” from two months ago, re-asked today, with a worse-informed AI and a me who had forgotten what I’d concluded last time. I was re-learning my own thinking. I needed a second brain that could actually remember.
The tools I tried first
Before I started building, I tried the obvious things. Everybody’s first reach.
Notion. Good for documents. Hostile for conversations. I’d paste a chat, format it, add tags, then never look at it again because pasting is too much friction for something I need to do a dozen times a day. And Notion’s search is good for titles, bad for ideas.
Obsidian. Same issue, plus the additional friction of markdown files on disk. Power users love Obsidian. I’m a power user. I never used it past week two.
Readwise and the “highlight” tools. Built for articles and books — not for the shape of a conversation, which is Q-and-A-and-followup-and-clarification and occasionally a code block. Square peg, round hole.
Mem, various AI-note apps. Closer. But none of them imported from the platforms I was actually using. I’m an AI polyglot — Claude for deep thinking, ChatGPT for fast drafts, Gemini for a second opinion, DeepSeek and Grok for specific kinds of work. No tool I tried let me bring all of my conversational history into one unified system.
Browser export scripts. I actually wrote three of these before I admitted I was building a product. The third one produced JSONL files that another AI could reliably parse. That’s when I realized the problem was bigger than a script.
The afternoon I stopped searching and started building
There’s a specific moment I remember. I was trying to decide whether to use PostgreSQL or MongoDB for a side project. I’d had four conversations about this across three platforms over six weeks. I spent an hour trying to find them. I found two, both inconclusive, and ended up re-asking, frustrated, at 11 PM on a [day of week, season].
Somewhere around midnight I opened a blank editor and typed: “What if my AI chats were actually an external memory system instead of a diary?”
That line is still in the commit history of the GRASPPY repo, from commit zero.
The next morning I had a 48-hour prototype. Clunky. Ugly. Chrome extension that grabbed the Claude chat DOM, a Node script that parsed the HTML, a SQLite file with 12 conversations in it. Good enough to prove the idea. Bad enough to be embarrassing. I’ve been iterating on it ever since, building a system to capture and organize AI knowledge from every conversation into a searchable second brain.
Recovered content from The problem I couldn’t stop thinking about
Meet GRASPPY
What it actually is, in one sentence
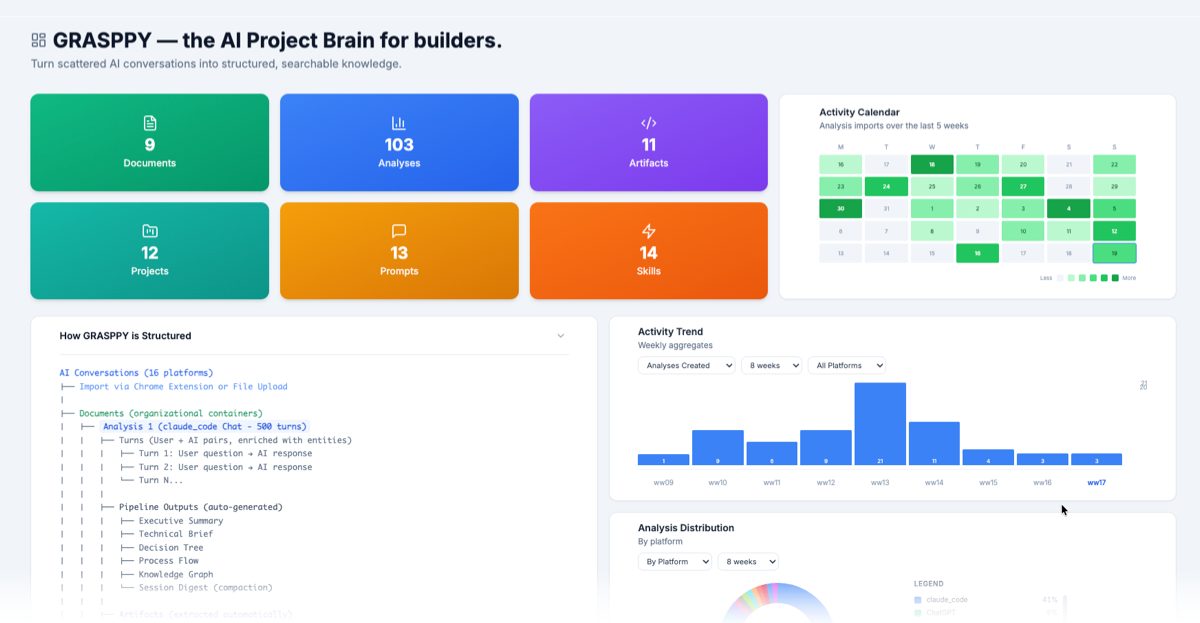
GRASPPY turns scattered AI conversations into organized, searchable, connected AI memory — with one-click export from 17 platforms and a pipeline that surfaces patterns you didn’t know were there.
That’s the elevator pitch. Here’s what that actually means in practice.
You click a button in your Chrome extension while looking at any conversation — Claude, ChatGPT, Gemini, Grok, DeepSeek, Perplexity, Mistral, GitHub Copilot, TypingMind, Replit, Bolt, Lovable, Voila, plus some markdown-import paths for Cursor, Windsurf, and Claude Code. The chat lands in GRASPPY. A pipeline processes it. When you come back to it, it’s not a transcript anymore — it’s a structured record with the ideas pulled out, the artifacts (code, documents) separated from the discussion, the topics linked to other topics you’ve discussed, and the decisions called out.
That last part is the thing. GRASPPY doesn’t just store; it finds. Two weeks after you’ve had a conversation about database schema, you can search for “how did I think about foreign keys” and it surfaces — with the context of the conversation it came from, effectively becoming your external memory system for AI knowledge and interactions.
Who it’s for
I’ll be honest: I built GRASPPY for myself. The target user looks a lot like me — a solo or small-team builder who uses AI for thinking, not just for autocomplete.
That said, after 12 months I’ve realized who else it fits. Researchers who consult models on literature. Founders running on AI for everything from pitch drafts to hiring. Developers who’ve effectively replaced Stack Overflow with Claude. Anyone who’s had the experience of saying “wait, I asked this before” and not being able to find it.
If you interact with AI models more than you interact with most humans (no judgment — I’m there too), and you need AI memory to capture all that AI knowledge from your conversations, this system is probably for you.
What makes it different
Three things set GRASPPY apart. There are more, but if I had to pick three at dinner with someone who asked “how’s it different from Notion”:
The Chrome extension covers the platforms you actually use. Seventeen, last count, and growing. Notion doesn’t import from ChatGPT. Obsidian doesn’t import from Gemini. I spent six months making extractors that reliably capture the DOM on each platform without breaking when they push UI updates — which they do, constantly. This is the least glamorous part of the codebase and the one that took the longest.
The 7-stage processing pipeline actually understands a conversation. Most “AI note tools” dump your chat into a vector database and call it done. That gives you search, but it doesn’t give you understanding. GRASPPY runs every imported chat through a structured sequence — parse, enrich with entities, cluster into topics, group related items, assemble outputs, finalize. More on this in the next chapter. It’s the difference between a box of photos and a photo album.
The AI memory system carries the real load. GRASPPY has a memory architecture where your AI knowledge accumulates across sessions, with the user always in control. It’s the thing I couldn’t find anywhere else — an external memory system where my AI-mediated thinking becomes durable instead of ephemeral. Think of it as a second brain that actually remembers.
A walk-through, the short version
You’re working through a gnarly architectural decision with Claude. You go back and forth over 30 turns. You make a choice. You move on. Two weeks later you hit a bug that’s related — you half-remember the reasoning but not the specifics.
In the old world: you either dig through your Claude history (slow, imprecise) or you re-ask (wasteful, possibly a different answer this time). In GRASPPY: you search “[whatever the topic was]” — it surfaces the full conversation, the specific turn where you made the decision, the related artifacts you built around it, and a link to two other chats where you’d touched the same concept but in a different context.
That’s the happy path. Most of what’s interesting about GRASPPY is making that happy path reliable for preserving AI memory as a second brain for external knowledge.
Recovered content from Meet GRASPPY
Under the hood — without the engineering
Raw chat is not knowledge
Every AI note tool I looked at assumed the same thing: if you can search the text, you can use the knowledge. That’s not true, and here’s why.
A chat is a performance, not a reference. When you ask Claude “what should I name this function?”, Claude doesn’t write a naming guide — Claude gives you one name, maybe two alternatives, tailored to what you just said. The value of that exchange isn’t the three words of the answer; it’s the relationship between your specific problem and the principle Claude surfaced to solve it.
If you index only the text, you lose the relationship. You get “Claude recommended handleUpload” divorced from the context of what was being uploaded, what the surrounding code looked like, why you rejected processFile. The search finds the string; it doesn’t find the insight.
GRASPPY treats a conversation as structured material waiting to be refined. The pipeline is how it does the refining, transforming raw dialogue into organized knowledge memory.
The 7-stage pipeline at 30,000 feet
Here’s what happens, in plain language, after you click the Chrome extension button:
Parse. The raw HTML or JSONL or markdown is converted into a structured turn-by-turn record. Each turn gets numbered, timestamped, and tagged with who said it. Code blocks and artifacts are extracted and stored separately so they can be referenced without drowning the conversation in syntax. This stage is pure code — no AI model involved. It has to be boringly reliable because everything downstream depends on it.
Enrich. An AI model reads each turn and pulls out the interesting stuff: people, places, tools mentioned, decisions made, questions asked, concepts introduced. This produces a structured shadow of the conversation that the next stages can reason about.
Cluster. Now that we know the entities, the pipeline groups related turns. A 30-turn conversation might be 3 real topics — we separate them. This is where chats start to become searchable in a meaningful way instead of just a keyword way.
Group. Clusters from this conversation get compared against clusters from previous conversations. If you’ve talked about PostgreSQL schema design four times over two months, they link up. This is the move that turns a chat log into AI memory that functions like an external cognitive system.
Assemble. The pipeline generates 10 different outputs from the processed conversation — summaries at different levels, a decision log, an artifact list, a Q&A extract, a “what did I learn” view. Each output has a purpose. You don’t have to read the 30 turns; you read the view that matches what you’re doing.
Complete. Cleanup, persistence, finalization. The boring-but-critical stuff that makes the system self-healing when something goes wrong mid-pipeline.
There’s a reason this can’t be done in one AI call. I tried. I burned a lot of API credits proving it. Conversations with real depth exceed what any single model can hold in context while also doing structured extraction and cross-referencing and producing 10 different outputs. Breaking it into stages means each stage can be tuned independently, each stage can use a different model if needed, and failures at any single step can be recovered without re-running everything upstream.
Why multi-model matters
GRASPPY isn’t locked to one AI provider. The first two stages run on a fast, cheap model (currently Haiku) because they need to be reliable and high-volume. The middle stages — where the real thinking happens — are user-configurable. You pick the model based on your budget and your taste.
This is important because no single model is best at everything, and the models you can afford to run over every conversation are different from the models you want for your deepest AI knowledge work. GRASPPY lets you match the tool to the job, ensuring your second brain adapts to your specific needs rather than forcing you into a one-size-fits-all solution.
What I keep closed and why I’m open about the rest
You’ll notice I’ve explained the pipeline conceptually but haven’t shown you the prompts. That’s deliberate.
The architecture — the 7 stages, the multi-model split, the enrich-then-cluster ordering — is an idea. Ideas are meant to be shared. If some of this inspires you to build something similar, that’s a good outcome, because the world of AI knowledge tools is early and needs more experiments, not fewer.
The prompts, though — the actual text that the pipeline sends to the models — those took roughly a hundred hours of iteration to get right. They’re the protocol that makes the downstream parsing work. They’re not secret because I’m paranoid; they’re private because they’re the concrete artifact of a lot of failed attempts. Sharing them wouldn’t teach you much. Rebuilding a system that uses them would still require rebuilding the thirty-something tables of database schema, the dedup logic, the AI memory mirror, the sync architecture, and everything else around them.
So: the architecture is open, the code is (mostly) open, the prompts stay with me. I think that’s the right trade.
Recovered content from Under the hood — without the engineering
Solo, 12 months in
The week I lost — and how it changed everything
On March 30, 2026, I destroyed a week of my own work.
The context: I’d been building a documentation system inside GRASPPY, one of several “project types” the platform supports. I had organized it into 7 sections with about 300 nodes of content — a week of careful structuring, rewriting, linking. This external memory system was meant to be the foundation for all my project documentation and AI memory management. The way GRASPPY’s schema worked at the time, deleting a project cascaded through foreign keys and wiped every child node attached to it.
I typed a DELETE query to clean up what I thought was a duplicate staging project. The query was correct. The project was the real one.
Everything was gone in about 80 milliseconds.
I sat there for maybe ten minutes not moving. Trying to remember if I had a backup. (I didn’t, not of that project specifically.) Trying to remember how much of it was reconstructible from notes. (Some, not most.) Trying to decide whether to quit.
I didn’t quit. But I did something I should have done a year earlier: I wrote a rule. An actual, enforced, documented rule that says: never delete any user data without explicit and clear permission. Not mine, not anyone’s. STOP → TELL → SHOW → WARN → WAIT, every time. That rule is pinned to the top of every Claude Code session I run. It’s in the project’s CLAUDE.md file. It’s the first rule, and it will remain the first rule forever.
The lesson wasn’t “back things up.” That’s obvious. The lesson was that speed was costing me more than it was saving me. A solo founder who moves fast is an asset; a solo founder who moves sloppy is a liability to himself. I’ve been slower since March 30. Steadier. And the truth is, I ship more now than I did when I was “moving fast.” There’s no time tax to being deliberate. There’s only the time tax of rebuilding what you destroyed.
100 hours on prompts nobody sees
Last month I spent about two solid weeks tuning a single prompt. It’s the one GRASPPY uses to export a Claude Code session into a structured JSONL file that the import pipeline can process.
Two weeks. On one prompt. A prompt the user never sees.
The reason: Claude Code JSONL files have a specific quirk. When the context window fills up, the session gets compacted — a summary is inserted in the middle of the file, and the rest of the session continues. The compaction line has a specific signal (isCompactSummary: true), but older sessions predate the flag. And the continuation message reuses the same promptId as the message before the compaction, which means a naive parser silently merges the compaction into the wrong turn.
To find this, I had to export sessions that spanned 10+ compactions, trace where records were landing in the database, and figure out why some of them were missing. Each bug fix surfaced the next bug. The prompt grew from 30 lines to 150, every line earned by a specific failure case.
When it finally worked — when I could reliably export a 60-compaction session with every single segment in the right place and none of them fused together — nothing visibly changed for the user. They just clicked the same button they’d been clicking. The export worked. That was the feature.
There are probably ten things in GRASPPY like this. Invisible work that took ten times as long as it looks. It’s the part of the job that’s hardest to explain to anyone who hasn’t done it — the part that doesn’t make for a good demo, doesn’t photograph, doesn’t tweet well. But it’s the part that makes the tool feel solid instead of flaky, the foundation that lets it function as a reliable second brain rather than just another export utility.
I think about this when I read Twitter threads about “MVP in a weekend.” You can ship an MVP in a weekend. You can’t ship a tool that feels good in a weekend. There’s no shortcut I’ve found.
The hardest part isn’t code
Code is the easy part. I mean that seriously. After twelve months, I’ve come to believe that the genuine difficulty of building a product like this isn’t technical. The hard things are:
Deciding what NOT to build. I have roughly forty features I could add tomorrow that a user would say “oh yeah, nice to have.” The skill I’ve been forcing myself to develop is saying no — to good ideas, because good ideas are the ones that bury a solo founder. Every feature I ship needs to live with me for the life of the product. I think about that a lot before I start building.
Writing the thing you’re reading. Shipping code is effortless compared to writing a sentence someone will care about. I’ve started and deleted this chapter four times. The specific kind of vulnerability it takes to tell a stranger “I lost a week of work” is a muscle I haven’t built. It’s a muscle I’m choosing to build now, in public, because the alternative — working in silence for another year while the project slowly becomes invisible — is a worse outcome.
Sleep, family, the life outside the laptop. I won’t belabor this. If you’re building solo you know exactly what I mean. I’m still working on this one and I don’t have advice; I’m a case study, not a mentor.
Translating AI knowledge into user value. Understanding what’s possible with language models is one thing; figuring out which AI memory capabilities actually matter to someone trying to build their second brain is entirely another.
Why I keep going
There was a moment a few months in when I used GRASPPY to answer a question for Claude. Claude was helping me debug something and asked “have we discussed this before?” — and instead of guessing, I searched GRASPPY, found the prior conversation from six weeks earlier, and pasted the relevant context back into the session.
Claude said something like “oh, that’s useful, that changes my recommendation.” And it did.
That’s the moment. That’s the thing I couldn’t have had without building it. My AI chats, compounding. My own thinking, persistent, searchable, mine. It’s the closest thing I’ve experienced to the feeling that science fiction promised about computers in the 1980s — a tool that gets better the more you use it, because you’re getting better, and the tool is tracking along with your growing knowledge. A true AI memory system that becomes an extension of my mind.
I’ll keep going as long as that feeling is there. So far, it’s there more often every month, not less.
Recovered content from Solo, 12 months in
Where this goes
The Journal you’re reading is part of the plan
You’re reading this on GRASPPY’s journal. I just finished building the journal feature — literally this week. The feature exists because I decided to stop working in silence. Twelve months of head-down execution got me a product I’m proud of and an audience of approximately three people (who are mostly my family).
I’m going to write in public now. Sometimes about GRASPPY’s engineering — a particularly gnarly bug, an architectural choice that almost bit me, a decision I’m still not sure about. Sometimes about the solo-founder experience — what I’m afraid of, what’s working, what isn’t. Occasionally about the industry — the AI tool landscape, AI knowledge systems, what I’m learning from users, where I think things are heading.
I’m calling this a journal on purpose, not a blog. “Blog” carries an implicit expectation of polished, finished thought. “Journal” is honest: it’s a running log of where I am, a second brain for the building process. Some entries will be short. Some will be messy. That’s the point.
Roadmap, at 30,000 feet
I won’t give you dates because I’ll miss them. But here’s where my head is:
The next 1–3 months: ship stability. GRASPPY is past MVP but not past polish. The existing features need to feel instant. Onboarding needs to be two minutes, not ten. The 17 platform extractors need to stay unbroken through whatever UI redesigns the AI platforms ship next.
3–6 months: quietly open GRASPPY up to early users. Not a marketing launch. Invitations, one at a time, to people who’ll give me real feedback. The bar for “ready” is: a stranger can use it for a week without me holding their hand.
12+ months: I’m still figuring out the shape of this. The instinct is to stay focused on the individual knowledge worker, not pivot to teams, not chase enterprise. The long bet is that AI-mediated AI knowledge work is about to become a massive category, and the tools that will win are the ones that treat the individual as the unit of work — not the committee. Think AI memory for the AI age.
What I need from you
If you read this far, I want to ask two things.
Subscribe to the journal — the form is right on this page. I’ll write something meaningful once a week. I won’t sell to you; I don’t even have a thing to sell yet. I’ll tell you what I’m building, what’s breaking, what I’m learning. If that’s valuable, stay. If it’s not, the unsubscribe link works.
Tell me who you are. Reply to the confirmation email or send me a note at [my email / contact form]. Tell me one thing: what’s the one AI knowledge conversation you wish you could find right now? I’m not pitching GRASPPY to you — I’m trying to understand if the thing I built for me is also the thing you need. Maybe you’re looking for a digital thinking partner that actually collaborates with you, or something else entirely. Your answer shapes what I build next.
Sign-off
Twelve months ago I had a graveyard of tabs and a nagging feeling that I was forgetting my own thinking. Today I have a tool that catches it.
If anything in this post resonated — the frustration, the solo-builder loneliness, the specific flavor of satisfaction when your own tool helps you answer your own question — I’d love to walk this next stretch with you.
— Gennady Building GRASPPY from sunny California, one deliberate commit at a time
Thank you for reading. If you want to know when the next post lands, drop your email below. If you want to tell me this was useful (or how it wasn’t), the contact form is below that. Both help.
Recovered content from Where this goes
Recovered Structural Content
Recovered content from AI Knowledge Management: Build Your Second Brain System
Related posts

Chat Analysis AI: Six Months of Chats - Any Answer In 10 Seconds
Learn why chat analysis AI matters for organizing your conversations. Discover how to search and preserve your AI chats instead of losing valuable insights.
AI Development Workflow: The Supervised AI Story
Discover how supervised AI development came about and why a structured AI development workflow changes everything. Learn the founder story behind context engineering.
AI Hallucination Example: When LLMs Shift Blame
Discover a real AI hallucination example showing how LLMs deflect responsibility. Learn to spot confabulation patterns in AI workspace interactions.